The Serverless Monolith

At Metaview, we help companies run amazing interviews. We achieve this in a number of ways including training interviewers with automated interview shadowing and coaching them with personalized, contextual feedback.
To do that we’re building a SaaS application that has many different components and, importantly, a growing number of engineers building it. Choosing an architecture for its backend systems is non-trivial and is critical to our success.
In this post, we’ll explore how we think about the monolith vs micro-services question and how we ended up leveraging serverless.
The Common Journey
Throughout my career, I’ve seen products at 3 companies start off with a monolithic style backend application and then transition to micro-services as their systems evolved: VMware, Uber, and Docker.
The driving reasons for moving away from a monolith have always been mostly the same:
- Costs pile up as infrastructure gets over-provisioned to support the wide range of workloads each application instance has to support.
- Velocity decreases as deployment pipelines become slow and complex.
- System reliability and engineer responsibility worsen as single deployments start batching multiple changes together.
- Development experience degrades as the application is impossible to run locally and deploying it anywhere is a nightmare.
At the end of the day, it’s customers who suffer as the product is unreliable, and it takes a long time for improvements to reach them.
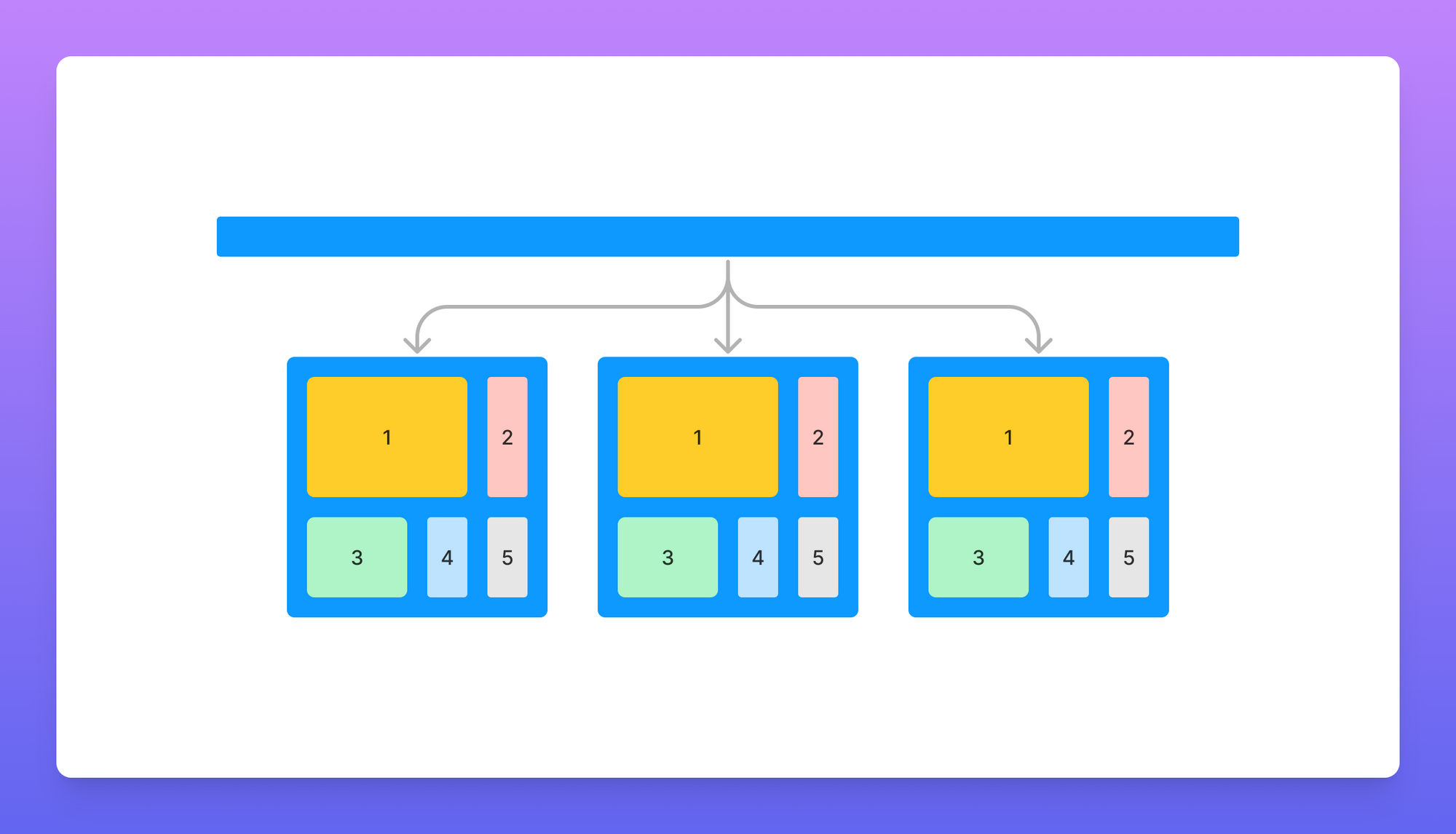
The applications are then split up into multiple micro-services based on domain boundaries, each one with its own workloads, database, deployment pipeline, and codebase.
This comes with problems of its own:
- Infrastructure costs and complexity increase to support the constantly growing number of applications.
- Reliability drops when services start depending on each other in previously unforeseen ways as the domain boundaries were impossible to predict accurately.
- Velocity decreases as code sharing and multi-service changes start becoming harder and harder, especially if multiple programming languages and frameworks are introduced.
- Endless migrations start taking up a lot of engineering time as every service owner has to ask all of their consumers to adapt to any changes they want to make.
Teams then start considering monorepos, common library versions across services, restricting the choice of programming languages and frameworks — things that were a given while operating a monolith.
All the while, these internal migrations, albeit large and costly, don’t impact customers in a direct, significant way.
I would argue that one of the main causes for this journey is the coupling of infrastructure and domain boundaries.
In the monolith world, the whole application is deployed as one piece. In other words, every change is assumed to affect the whole domain, and the infrastructure is scaled accordingly. With micro-services we split up domains and infrastructure in a one-to-one fashion, which is good in a frozen state, but, becomes problematic as the business morphs and the domain boundaries move much faster than infrastructure ones. This often leads to mini-monoliths appearing in a micro-services environment and needing costly migrations to split them up again.
Metaview’s Approach
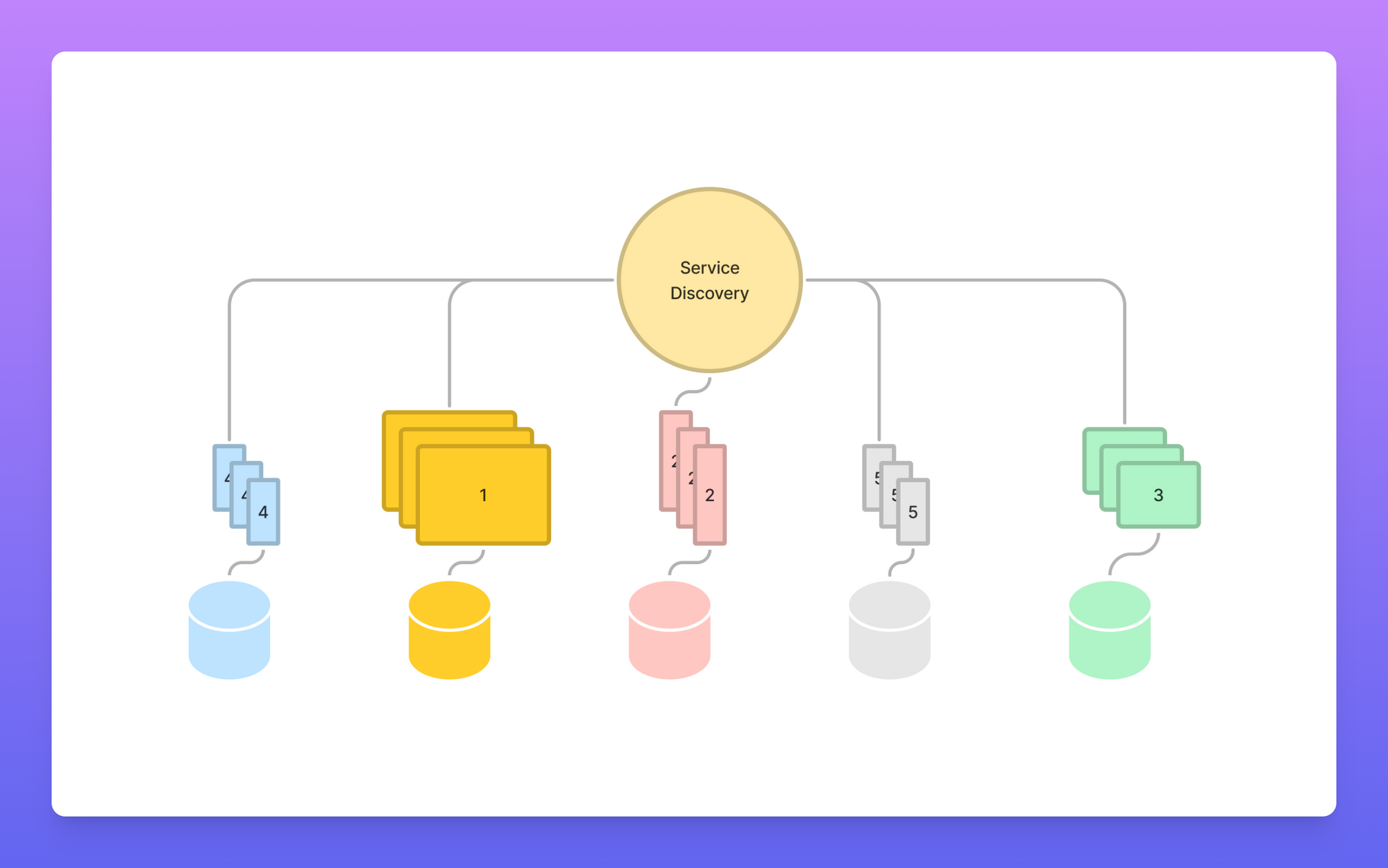
At Metaview, we decided to heavily lean on the serverless paradigm. This has given us different benefits and drawbacks, but, crucially, it allows us to scale each workload independently, deploy changes in whatever grouping we like, and change that grouping in a cheap way. It essentially allows us to reduce the coupling between domain boundaries from infrastructural ones.
To optimize for customer experience, engineer productivity, systems reliability, and infrastructure costs (in that order) we currently utilize the following setup:
- All backend code is in a monorepo in one language with the following [simplified] structure:
- core/services/service_1, service_2, ..., service_n
- stacks/stack_1, stack_2, ..., stack_n
- Services represent business logic split into different domain units. Each service is essentially a class with some business logic, that can be used across stacks.
- Each stack is a group of serverless functions, which are deployed together. They can easily be moved around, and are usually grouped according to the type of workload they perform, e.g. serving web app traffic, ETL, event-based processing, or certain types of 3rd party integrations. Each stack is deployed independently and only if there are changes made to it.
- External libraries are shared under core, with the exception of stack-specific ones, e.g. GraphQL.
- Every stack and every function can be run locally by relying on production/staging dependencies.
- The OLTP database is shared across stacks.
This has a lot of the components of a monolith — the monorepo, the shared database, and common library versions. But, it alleviates many of the pain points — workloads are scaled and deployed individually, the local development experience is good, and large code changes are straight-forward. Stacks are very easy to move or create new ones. Costs scale linearly with traffic.
Serverless is much like wireless. Wireless doesn't mean there are no more wires involved, it's just that you don't need to worry about them most of the time.
Upcoming Challenges
This setup is very dependent on the organization's size, and we expect to face some challenges with it as we grow. For example:
- Maintaining clear structure, ownership, and separation between core services over time — this setup requires some architectural guidelines for making sure that core services don’t depend on each other and are not structured in unhealthy ways. This now becomes much more of a DDD problem than an infrastructural one, and fixing issues is more often achieved through refactoring, rather than a costly migration.
- Making sure that our CI pipeline is quick and reliable — we’re likely going to need to spend some time on ensuring only the required tests are run on pull requests.
- Scaling up the database — having too much customer-generated data is a good problem to have, though we believe this can be pushed back a fair bit by utilizing the database well, e.g. not doing ETL on an OLTP database.
As it stands, the gains are far outstripping the losses.



